Una distribución de probabilidad ampliamente utilizada de una variable aleatoria discreta es la distribución binomial. Esta describe varios procesosde interés para los administradores.
Describe datos discretos, resultantes de un experimento denominado proceso de Bernoulli en honor del matemático suizo Jacob Bernoulli, quien vivió en el siglo XVII.
Empleo del proceso de Bernoulli.Podemos servirnos de los resultados de un número
1. Cada ensayo ( cada lanzamiento, en nuestro caso) tiene sólo dos resultados posibles: lado A o lado B, sí o no, éxito o fracaso.
2.La probabilidad del resultado de cualquier ensayo (lanzamiento) permanece 3. Los ensayosson estadísticamente independientes , es decir, el resultado de un lanzamiento no afecta al de cualquier otro lanzamiento.
Cada proceso de Bernoulli tiene su propia probabilidad característica. Pongamos el caso en que siete décimas partes de las personas que solicitaron cierto tipo de empleopasaron la prueba . Diremos entonces que la probabilidad característica fue de 0.7 pero podemos describir los resultados de la prueba como un proceso de Bernoulli sólo si tenemos la seguridad de que la proporción de los que fueron aprobados permaneció constante con el tiempo.
Des de luego, la otra característica del proceso de Bernoulli también deberá ser satisfecha. Cada prueba deberá arrojar tan sólo dos resultados (éxito o fracaso= y los resultados de las pruebas habrán de ser estadísticamente independientes.
En un lenguaje más formal, el símbolo p representa la probabilidad de un éxito y el símbolo q ( 1- p ) representa la probabilidad de un fracaso. Para representar cierto número de éxitos, utilizaremos el símbolo r y para simbolizar el número total de ensayos emplearemos el símbolo n.
Entonces tenemos que :| P | Probabilidad de éxito. |
| Q | Probabilidad de fracaso. |
| r | Número de éxitos |
| n | Número de ensayos efectuados. |
Existe una fórmula binomial:
Probabilidad de r éxitos en n ensayos es :
N! / R! (N-R)! PR QN-R
Recordemos que el símbolo factorial! Significa por ejemplo que es 3! = 3*2*1 = 6
Los matemáticos definen 0! = 1.
3.3 DISTRIBUCION NORMALLa Distribución Normal: una distribución de una variable aleatoria continua.
Una muy importante distribución continua de probabilidad es la distribución normal. Varios matemáticos intervinieron en su desarrolloentre ellos figura el astrónomo del siglo XVIII Karl Gauss, a veces es llamada en sus honor la distribución de Gauss.
Características de la distribución normal de la probabilidad.1.La curva tiene un solo pico, por consiguiente es unimodal. Presenta una forma de
2.La media de una población distribuida normalmente se
3. A causa de la simetría de la distribución normal de probabilidad, la mediana y la moda de la distribución también se hallan en el centro, por tanto en una curva normal, la media, la mediana y la moda poseen el mismo valor.
4. Las dos colas (extremos) de una distribución normal de probabilidad se extienden de manera indefinida y nunca tocan el eje horizontal.
Áreas bajo la curva normal.
El área total bajo la curva normal será de 1.00 por lo cual podemos
El valor de Z.
Z= Número de desviaciones estándar de x respecto a la media de esta distribución.
Z= x-m / s
X=valor de la variable aleatoria que nos interesa.
m = media de la distribución de esta variable aleatoria.
s = desviación estándar de esta distribución.
Las variables aleatorias distribuidas en forma normal asumen muchas unidades diferentes de medición, por lo que hablaremos de forma estándar y les daremos el símbolo de Z.



 (sumamos n veces 1 y luego dividimos por n)
(sumamos n veces 1 y luego dividimos por n)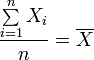




.svg)


 y s como
y s como  además se puede tener una mejor tendencia de medida al desarrollar las formulas indicadas pero se tiene que tener en cuenta la media, mediana y moda
además se puede tener una mejor tendencia de medida al desarrollar las formulas indicadas pero se tiene que tener en cuenta la media, mediana y moda